
📝 Publications and Preprints
* denotes equal contribution.
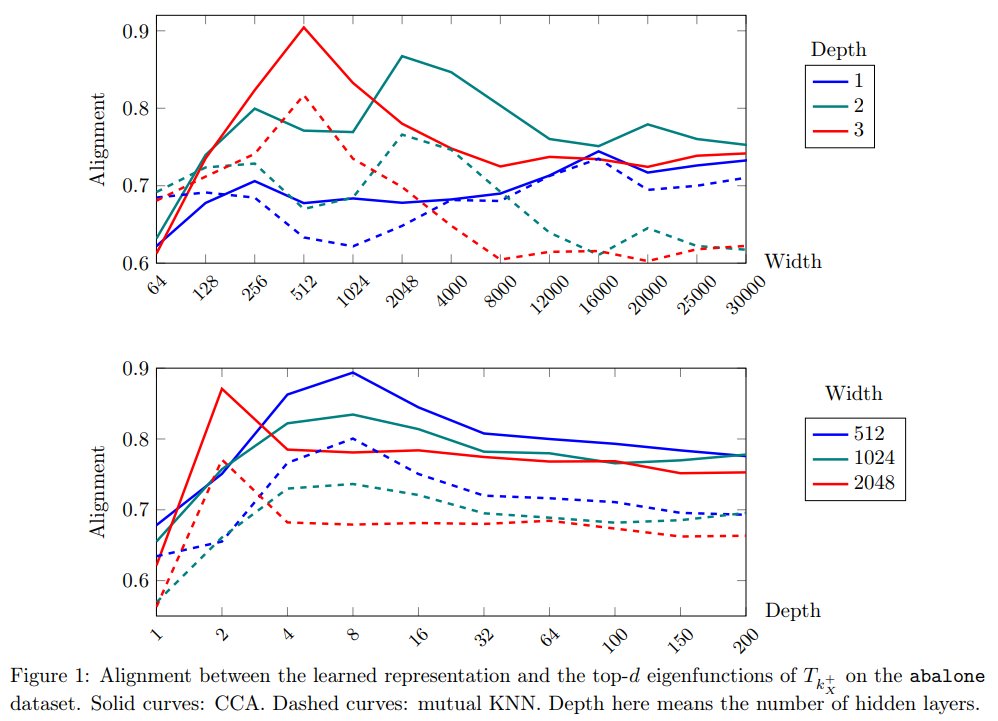
[ICML 2025] Contextures: Representations from Contexts
Runtian Zhai, Kai Yang, Che-Ping Tsai, Burak Varıcı, Zico Kolter, Pradeep Ravikumar
- Establish the contexture theory, which shows many representation learning methods can be characterized as learning from the association between the input and a context variable.
- Demonstrate that many popular methods can approximate the top-d singular functions of the expectation operator induced by the context, which we call the represetnation learns the contexture.
- Prove the representation that learns the contexture are optimal on those tasks that are compatible with the context. Thus, scaling up the model size will finally yields diminishing returns.
- Propose a metric to evaluate the usefulness of a context without knowing the downstream tasks.
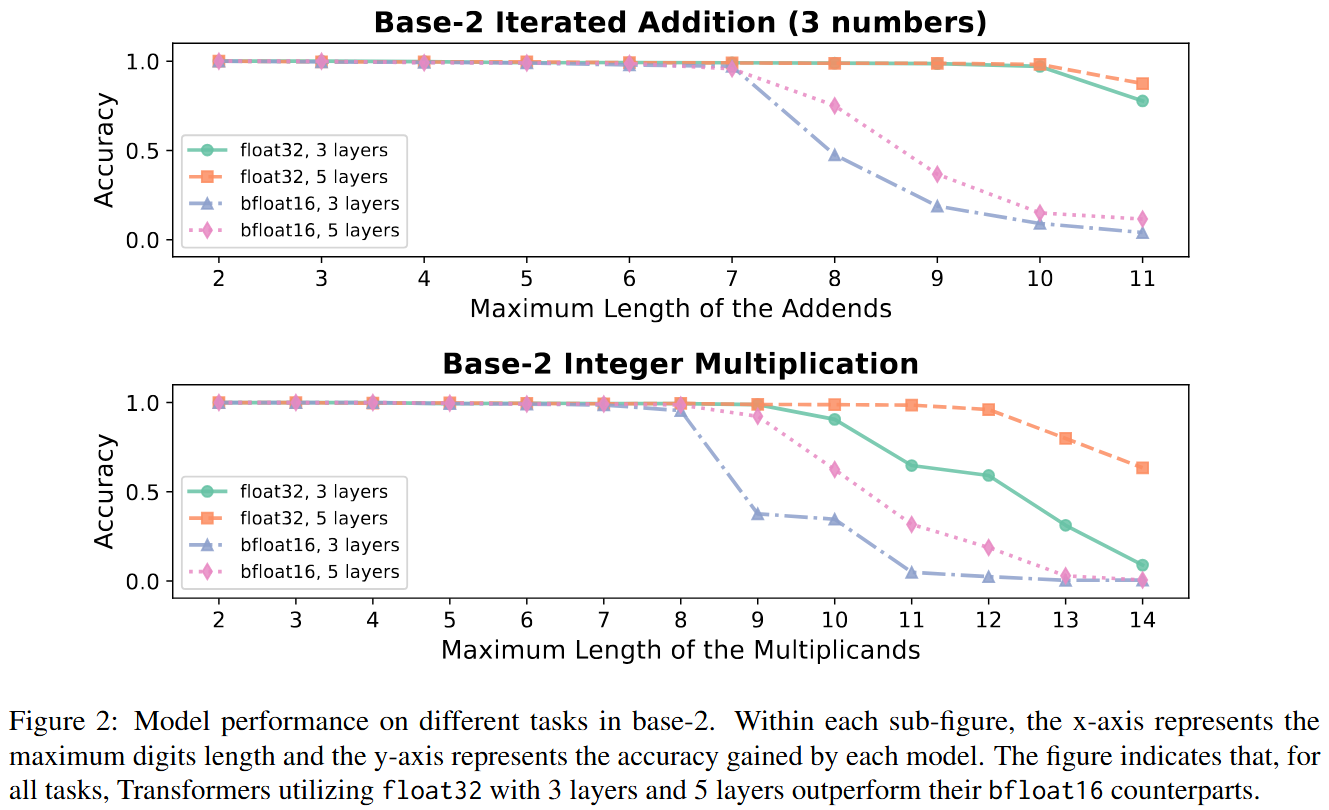
[ACL 2025 Findings] How Numerical Precision Affects Arithmetical Reasoning Capabilities of LLMs
Guhao Feng*, Kai Yang*, Yuntian Gu, Xinyue Ai, Shengjie Luo, Jiacheng Sun, Di He, Zhenguo Li, Liwei Wang
- Identify numerical precision as a key factor influencing the effectiveness of LLMs in arithmetic tasks.
- Theoretically demonstrate that Transformers with low numerical precision fail to address elementary arithmetic tasks such as iterated addition and integer multiplication, unless the model size increases super-polynomially with respect to the input length.
- Theoretically prove that Transformers with standard numerical precision can efficiently handle elementary arithmetic tasks with moderate model sizes.
[ICML 2024] Do Efficient Transformers Really Save Computation?
Kai Yang, Jan Ackermann, Zhenyu He, Guhao Feng, Bohang Zhang, Yunzhen Feng, Qiwei Ye, Di He, Liwei Wang
- Understand the capabilities and limitations of efficient Transformers, specifically the Sparse Transformer and Linear Transformer on their reasoning capabilities with Chain-of-Thought.
- Theoretically reveal that while these efficient Transformers are expressive enough to perform Chain-of-Thought reasoning, they require a model size that scales with the problem size, which finally offsets their efficiency.
- Theoretically prove that Transformers with standard numerical precision can efficiently handle elementary arithmetic tasks with moderate model sizes.
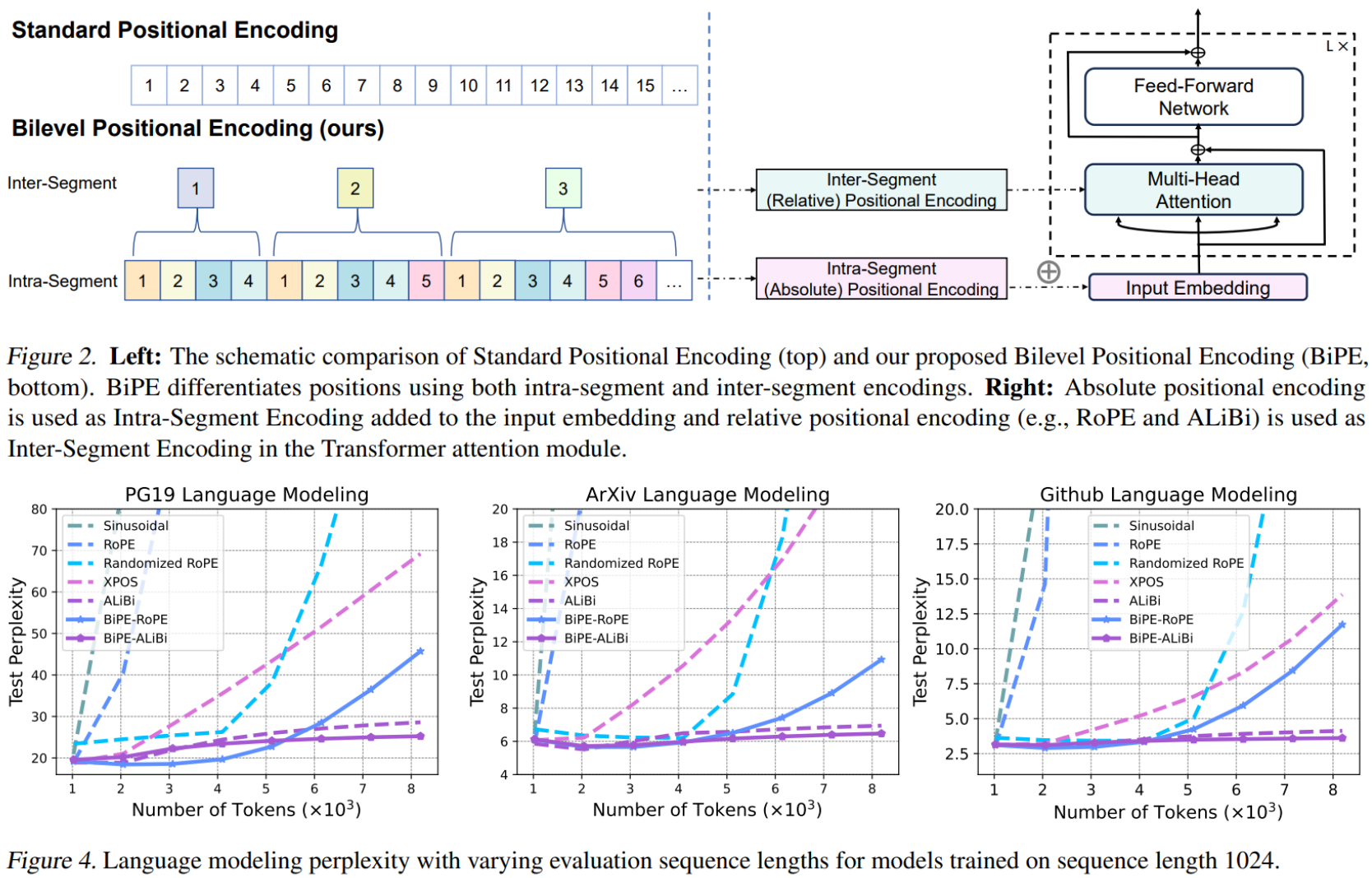
[ICML 2024] Two Stones Hit One Bird: Bilevel Positional Encoding for Better Length Extrapolation
Zhenyu He*, Guhao Feng*, Shengjie Luo*, Kai Yang, Liwei Wang, Jingjing Xu, Zhi Zhang, Hongxia Yang, Di He
[Code]
- Leverage the intrinsic segmentation of language sequences and design a new positional encoding method called Bilevel Positional Encoding (BiPE).
- The intra-segment encoding identifies the locations within a segment and helps the model capture the semantic information via absolute positional encoding.
- The inter-segment encoding specifies the segment index and models the relationships between segments, aiming to improve extrapolation capabilities via relative positional encoding.